
2020-12-26
3120

原创
PTB数据集介绍与预处理
1.PTB数据集介绍
PTB(Peen Treebank Dataset)文本数据集是目前语言模型学习中使用最为广泛的数据集,PTB数据集来源于Tomas-Mikolov网站,其中包含很多文件(如下图所示),但是我们只关心data文件夹下面的三个文件:ptb.test.txt、ptb.train.txt、ptb.valid.txt(如下图所示),这三个文件中的数据已经经过预处理,相邻单词之间用空格隔开,数据集中包括9998个不同的单词词汇,加上特殊符号
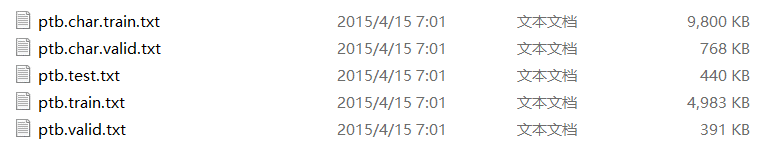
我们可以用记事本打开其中的一个文件“ptb.train.txt”发现:一共有42068行(句子),还有一些

2.载入PTB数据集
首先,我们先导入ptb.train.txt文件,让程序读取出不同的单词,并按频数存入名为“ptb.vocab”的文件:

import collections
from operator import itemgetter
raw_data = "ptb.train.txt" # 读取原始数据文件
vocab_output = 'ptb.vocab' # 输出处理好的文件
str_num = 0 # 统计整个文件中的单词数量
line_num = 0 # 统计整个文件中的行数
# ================================1.统计单词出现的频率================================
counter = collections.Counter()
with open(raw_data, 'r', encoding='utf-8') as f:
for line in f:
line_num = line_num + 1
for word in line.strip().split():
counter[word] += 1
str_num = str_num + 1
print('单词量:', str_num)
print('行数:', line_num)
print('单词量 + 行数 = 总单词量:', str_num + line_num)
# ================================2.按单词频率顺序进行排序================================
sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True) # 1.先排序
sorted_words = [x[0] for x in sorted_word_to_cnt] # 2.再根据顺序将元素添加到sorted_words
print('sorted_word_to_cnt前10项: ', sorted_word_to_cnt[0:10])
print('sorted_words前10项(未添加<eos>符号):', sorted_words[0:10])
# ============================3.需要在文本换行处加入句子结束符'<eos>'=====================
sorted_words = ['<eos>'] + sorted_words
print('sorted_words前11项(添加<eos>符号): ', sorted_words[0:11])
print('不同单词的数量:', len(sorted_words))
## ptb.train.txt文件中的数据已经将低频词汇替换成了'<unk>',因此不需要这一步骤
# sorted_words = ['<unk>', '<sos>', '<eos>'] + sorted_words
# if len(sorted_words) > 10000:
# sorted_words = sorted_words[:10000]
# ===================4.将sorted_words中的单词按顺序写入文件ptb.vocab=====================
with open(vocab_output, 'w', encoding='utf-8') as file_output:
for word in sorted_words:
file_output.write(word + '\n')
单词量: 887521
行数: 42068
单词量 + 行数 = 总单词量: 929589
sorted_word_to_cnt前10项: [('the', 50770), ('<unk>', 45020), ('N', 32481), ('of', 24400), ('to', 23638), ('a', 21196), ('in', 18000), ('and', 17474), ("'s", 9784), ('that', 8931)]
sorted_words前10项(未添加<eos>符号): ['the', '<unk>', 'N', 'of', 'to', 'a', 'in', 'and', "'s", 'that']
sorted_words前11项(添加<eos>符号): ['<eos>', 'the', '<unk>', 'N', 'of', 'to', 'a', 'in', 'and', "'s", 'that']
不同单词的数量: 10000
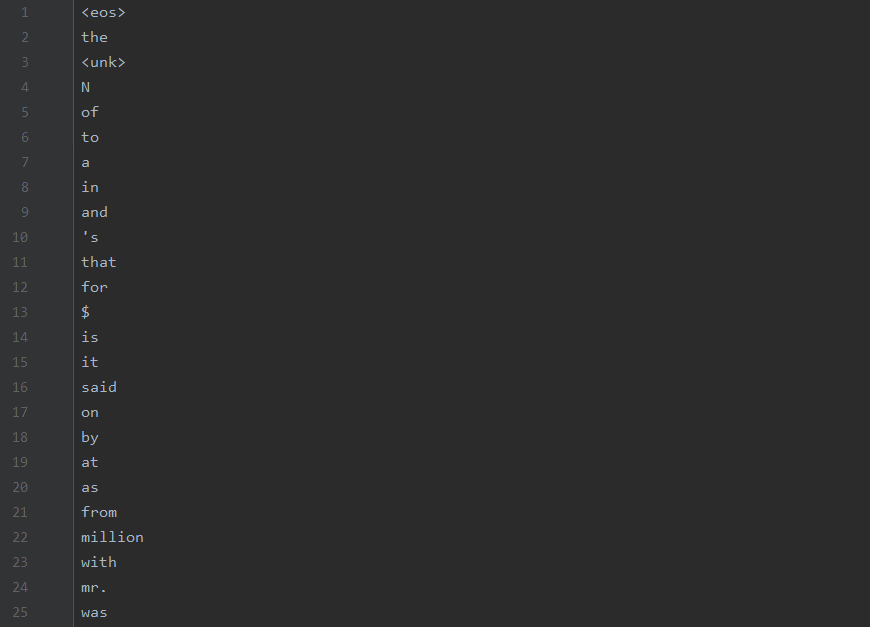
需要注意的是:我们将换行符用“

然后,我们需要根据原始数据文件“ptb.train.txt”和刚刚创建好的词汇表“ptb.vocab”,创建一个对应着单词id的原始数据文件‘ptb.train’,将里面句子中的单词全部替换成对应的id:
train_data = "ptb.train.txt" # 读取原始数据文件
vocab = 'ptb.vocab' # 读取之前创建的文件
output_train_data = 'ptb.train' # 输出处理好的文件
# ==========================1.读取词汇表ptb.vocab文件,并生成单词到单词编号的映射========================
with open(vocab, 'r', encoding='utf-8') as f_vocab:
vocab = [w.strip() for w in f_vocab.readlines()]
# ====================================2.生成'word_to_id'字典=========================================
word_to_id = {k:v for (k,v) in zip(vocab,range(len(vocab)))}
# =============3.创建一个函数:如果新的单词不在字典vocab中,没有对应的id,则替换为'<unk>'的id==============
def get_id(word):
return word_to_id[word] if word in word_to_id else word_to_id['<unk>']
# ===========4.先读取原始文件ptb.train.txt,再将其中的单词替换成对应的id写入创建好的输出文件ptb.train=======
fin = open(train_data, 'r', encoding='utf-8')
fout = open(output_train_data, 'w', encoding='utf-8')
for line in fin:
words = line.strip().split() + ['<eos>'] # 读取单词并添加<eos>结束符
out_line = ' '.join([str(get_id(w)) for w in words]) + '\n' # 将每个单词替换为词汇表中的编号
fout.write(out_line)
fin.close()
fout.close()
此时,目录中已经创建好了‘ptb.train’文件,打开发现句子中的单词已经变成了对应的id值。
参考资料
Training an LSTM network on the Penn Tree Bank (PTB) dataset---Github
Python
深度学习
神经网络



评论