标签
共
18
个
Python
28
机器学习
17
深度学习
16
神经网络
15
Java
10
其他
3
Android
4
MySql
2
书籍感想
2
数据结构与算法
2
Markdown
0
Linux
1
生活记录
1
HTML
0
LeetCode
0
CSS
0
JavaScript
0
高等数学
0
PTB数据集介绍与预处理
PTB(Peen Treebank Dataset)文本数据集是目前语言模型学习中使用最为广泛的数据集,数据集中包括9998个不同的单词词汇,加上特殊符号<unk>(稀有词语)和语句结束标记符(换行符)在内,一共是10000个词汇。近年来关于语言模型方面的论文大多采用了Mikolov提供的这一预处理后的数据版本,由此保证论文之间具有比较性。......


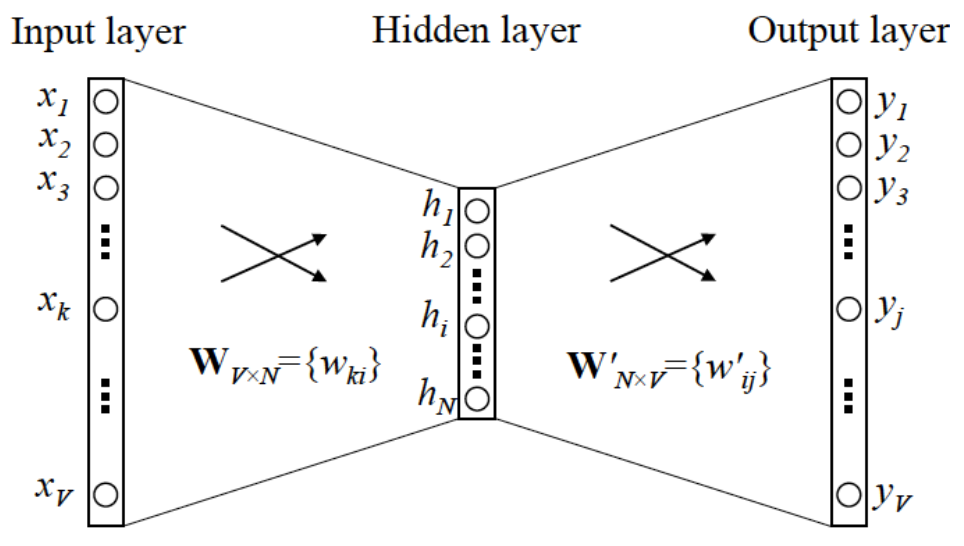
自然语言处理01---单词的分布式表示
我们平时使用的语言,如日语、英语,称为自然语言(Natural Language)。而自然语言处理(Natural Language Processing,NLP)就是处理自然语言的科学:简单的说就是一种能够让计算机理解人类语言的技术,进而完成对我们有帮助的任务......












机器学习手册08---特征工程(特征降维篇)
降维实际上就是降低特征的个数,最终的结果就是特征和特征之间不相关。降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。......

机器学习手册08---特征工程(特征提取篇)
特征提取涉及到从原始属性中自动生成一些新的特征集的一系列算法,降维算法就属于这一类。特征提取是一个自动将观测值降维到一个足够建模的小数据集的过程。对于列表数据,可使用的方法包括一些投影方法,像主成分分析和无监督聚类算法。对于图形数据,可能包括一些直线检测和边缘检测,对于不同领域有各自的方法。......

机器学习手册07---线性回归
线性回归是机器学习中最简单的有监督学习算法之一,事实上,由于它非常简单,有时,甚至不会认为是机器学习的一部分。无论你是否相信,当目标向量是数值(如:房价)时,线性回归及其扩展一直是常见且有效的预测方法......

机器学习手册06---KNN算法
KNN分类器是有监督学习领域之中,最简单且被普遍使用的分类器之一。KNN分类器一般被认为是一种懒惰的学习器。因为严格地说,它并没有训练一个模型用来预测,而是将观察值的分类判定为离它最近的k个观察值中所占比例最大的那个分类......

机器学习手册05---图像处理
图像分类是机器学习中最令人兴奋的领域之一,在将机器学习算法应用与图像之前,通常需要先将原始图像转换为算法可用的特征,我们将学习使用开源计算机视觉库(OpenCV)来处理图像。......


机器学习手册03---处理数值型数据
数值型数据是众多数据类型中,最能直观表现出数据特点的类型,但是对于机器学习算法中,大多数情况还需要对数值型数据进行处理,转化成其真正所需要的特征。......

机器学习手册02---数据整理的起点【分组】
经过上一篇对数据整理的初步认识,现在即将迎来数据整理的真正起点——分组操作......




